EF4 near Tabler, Oklahoma. May 24, 2011. (Brett Roberts via Flickr)
This is the first of a multi-part series that introduces a technique developed by the author to classify tornado events and tornado days. We will follow up with additional posts that demonstrate its uses.
Let me introduce myself — I’m a storm chaser. I live in… California.
Chasing tornadoes while living half a country away from Tornado Alley is a challenge, one that many people deal with each year. Fly out for a chase setup? Should I take the risk of buying an expensive plane ticket given the setup might bust? Chasecation in May? What if the tornadoes don’t show up?
As an out-of-region chaser, improving my chances of catching tornadoes is a key motivation. A natural starting point for such hopes is attempting to find the days where tornadoes are most likely in any given year.
But what days should be considered “tornado days?” All such days are not created equal.
Much of the current literature focuses on tornado counts or tornado intensities. I think there are a few flaws with that kind of analysis. Below, in the introduction to this method, I’ll give a few examples. For instance, let’s say I mark any day with at least 10 tornadoes as a tornado day. Here are some potential problem cases:
These kinds of cases are especially important to consider if I’m trying to classify tornado days as a storm chaser. As chasers, we tend to be less concerned about tornado strength or counts, and more about how many minutes of tornado action we can get within a given radius from a certain location. That idea is going to play a central role in this method.
Let’s start here with the idea of tornado-minutes. A naive approach might be to simply count total tornado minutes, but that doesn’t solve the case of tornado minutes being spread out spatially vs. focused in one area. The distribution and density of tornado minutes matters.
My method starts by taking an input of tornado segments and separating each segment into discrete points, with each point representing a position where a tornado has existed for one minute.
Example: an EF5 wedge tornado travels along Interstate 44 from Oklahoma City to Tulsa between 5 and 6 p.m. This setup would separate that tornado into 60 points spaced equidistant between Oklahoma City and Tulsa. Each point represents the interpolated position of the tornado at 5:01 p.m., 5:02 p.m., and up to 5:59 p.m., before the tornado lifts at 6 p.m. In the rest of this text, I’m going to refer to these points as “tornado-minute points”. (Note that in this method, “brief touchdowns” are counted as one minute.)
The next step involves clustering the tornado-minute points using the popular data-mining algorithm known as DBSCAN. DBSCAN finds clusters of densely-packed points from a larger dataset of points. Those points that do not fall within a cluster are labeled as outliers or noise. The parameters that go into DBSCAN are:
DBSCAN is primarily designed for spatial data, but it can be tweaked to incorporate geospatial-temporal data. In this variant eps is separated into distance (eps_km) and temporal (eps_min) components, and two points are densely-packed only if they are within both distance and time away from each other. Here are some examples of this in action in the context of tornado-minute points. Let’s say min_samples is 10, eps_km is 10, and eps_min is 10.
From these examples, we can conclude that, given we tune the eps and min_samples parameters properly:
From there, it is straightforward to assert that a tornado day is one where there is at least one cluster found from all the points obtained from tornadoes on that day.
Finally, the size of the cluster is simply the number of tornado-minute points, which equals the sum of each tornado’s longevity for all the tornadoes in the cluster. So three 10-minute tornadoes in a cluster would yield a cluster size of 30 minutes.
The clustering method requires complete spatial and temporal data (start/end * coordinates/datetime) to perform the breakdown of tornado segments into tornado-minute points. As of this writing, the Stom Prediction Center (SPC) database does not contain tornado end times, and some are missing end coordinates as well. The Storm Events database does contain the relevant information, but only back to 1996. Thus, the clusterable dataset of tornadoes only goes back 22 years. Nevertheless, this sample size is sufficient for purposes here.
Future iterations of this technique might involve using algorithms to back-fill temporal data before 1996 to expand the sample size.
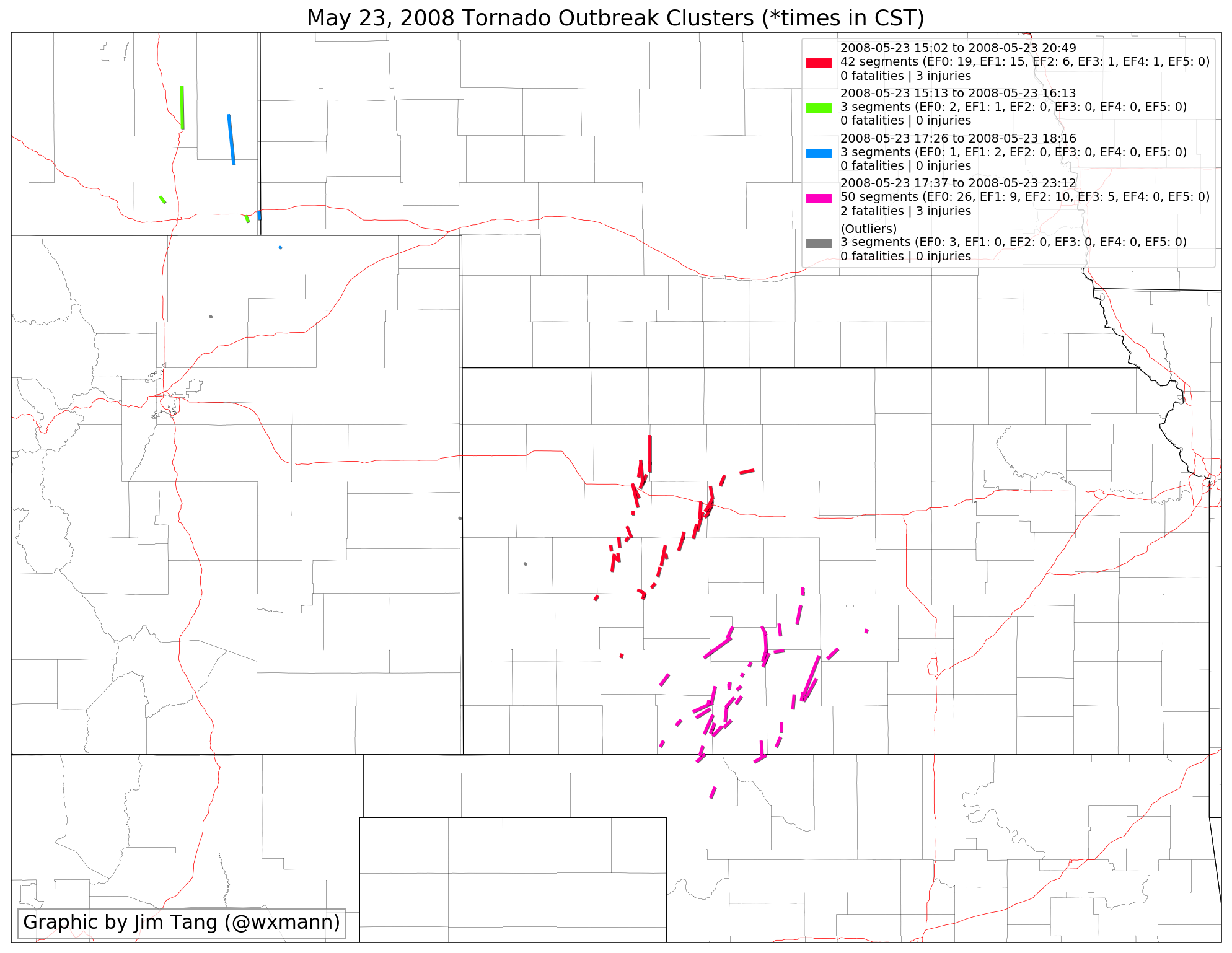
Finally, the algorithm isn’t perfect and will produce less-than-ideal clusters when a supercell goes long periods without producing a tornado. An example of this will be shown in the next section.
Enough talk, what does this clustering look like with real tornado outbreaks? The maps below are generated with the following parameters: eps_km=80, eps_min=60, min_samples=15.
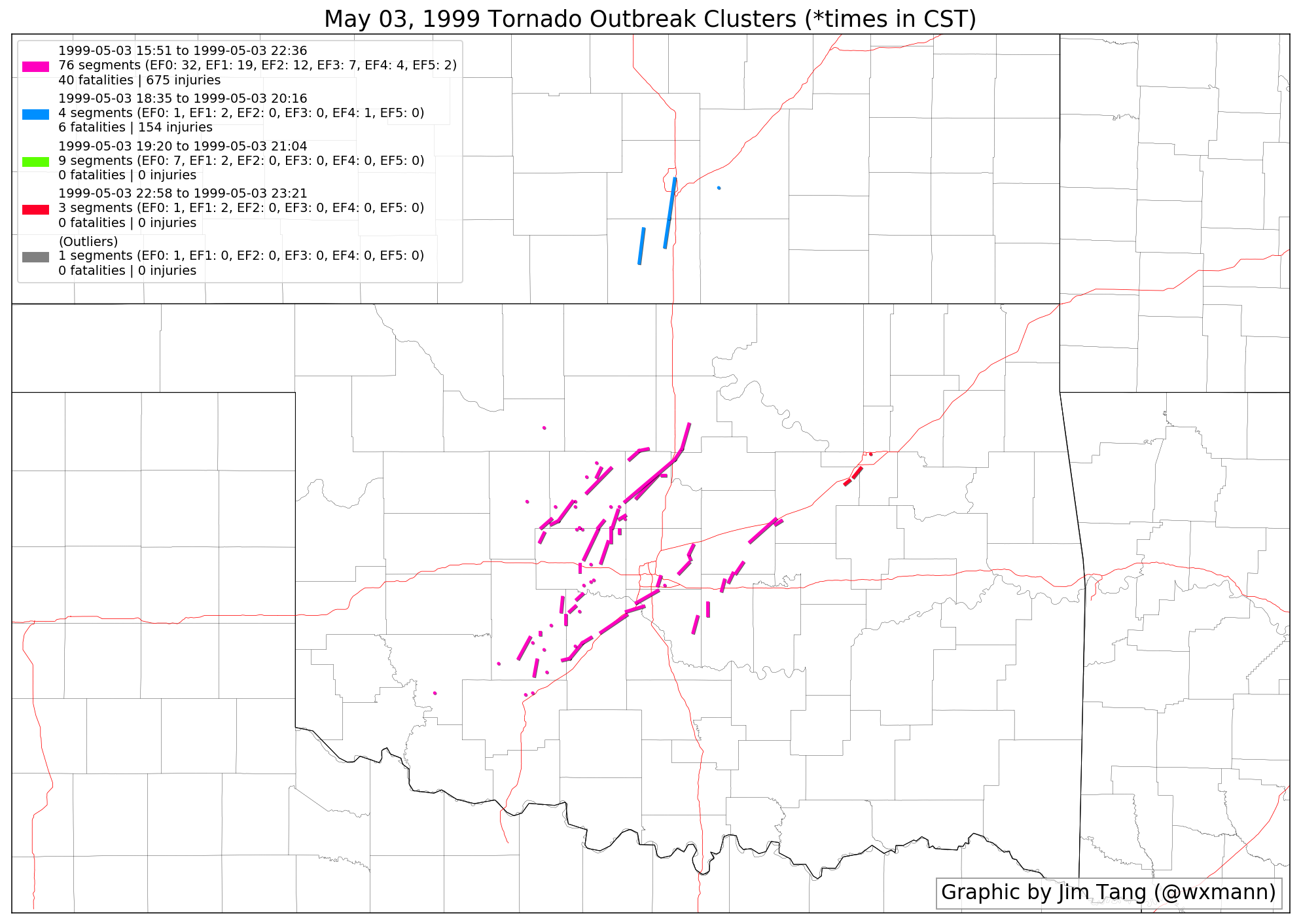
(The green cluster isn’t shown here because it’s outside the boundaries of this map.) Note here the Oklahoma City area tornadoes, the Wichita-Haysville area tornadoes, and the Tulsa-Sapulpa area tornadoes are split accordingly.
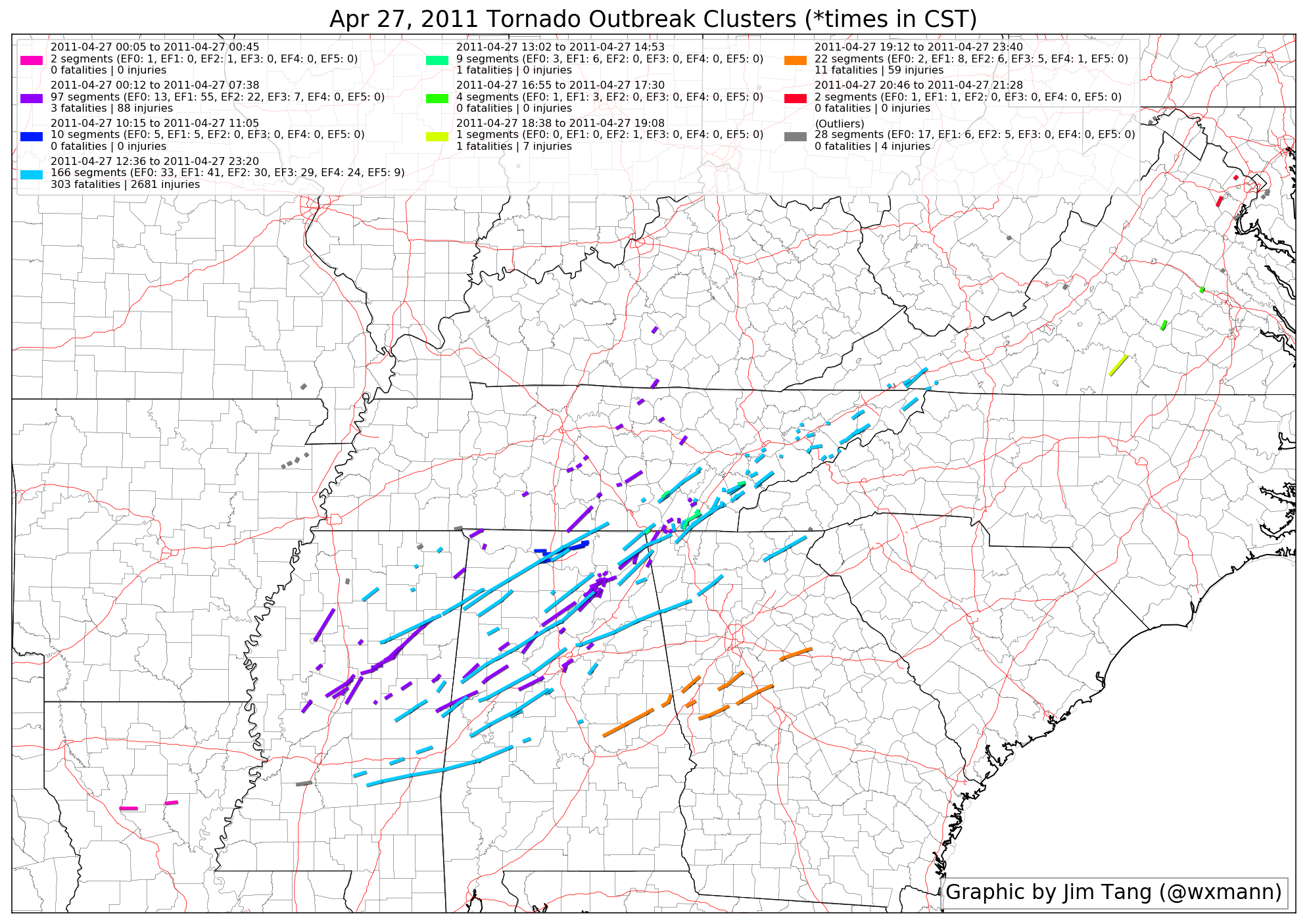
The clustering algorithm separates the three stages of the outbreak in Alabama very well: the morning MCS stage is in purple, the midday supercells near Huntsville are in dark blue, and the afternoon violent supercells are in light blue.
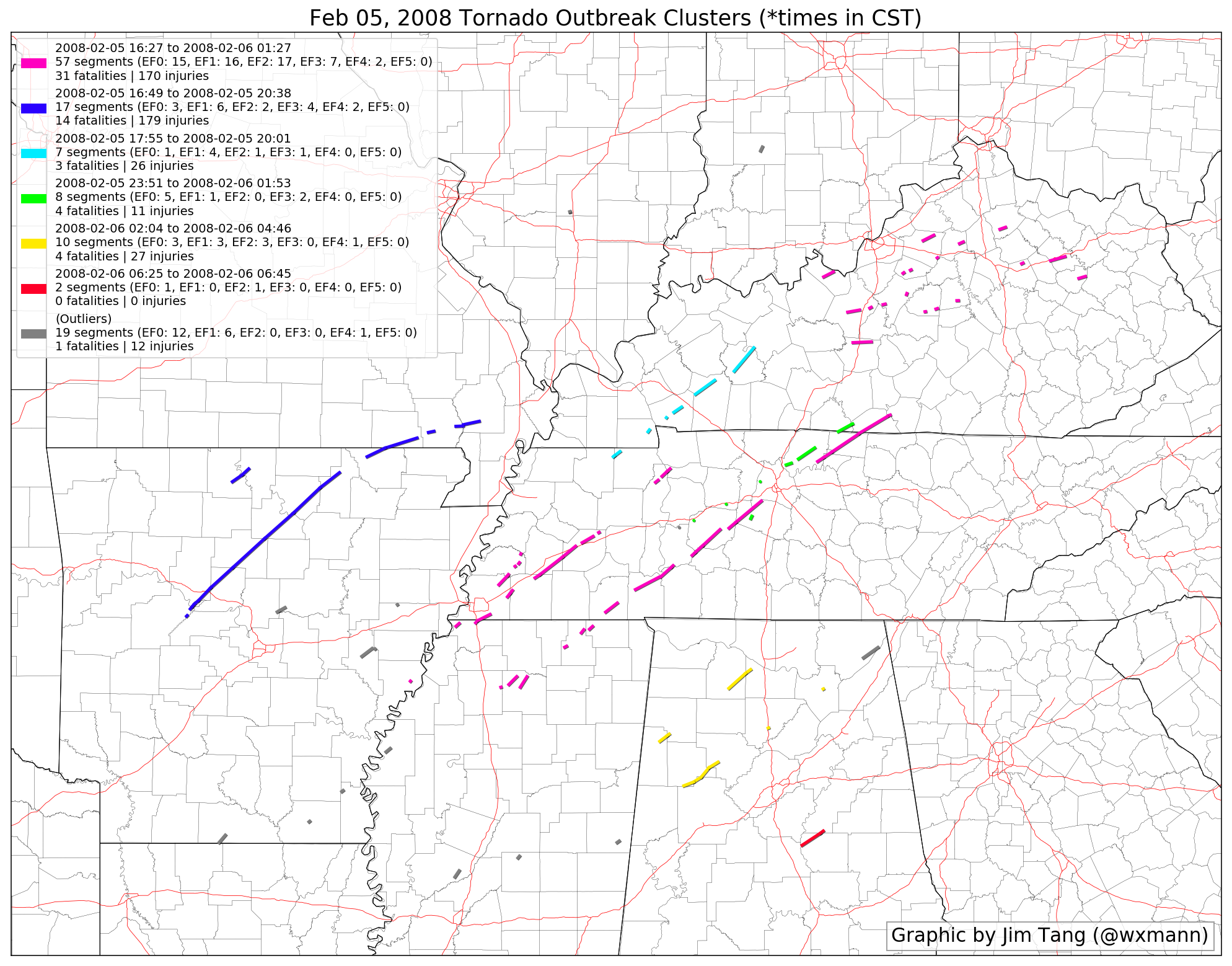
This is the example of the “less-than-ideal” case mentioned in the drawbacks section. The Jackson, AL EF4 tornado is awkwardly left out of the yellow cluster since there aren’t many tornado-minute points nearby. That particular supercell went through long phases of not spawning a tornado, which is reflected in the sparse tornado tracks nearby. Additionally, tornadoes associated with the MCS in KY are accidentally added into the magenta cluster, since they are so close in space and time to the supercell tornado northeast of Nashville.
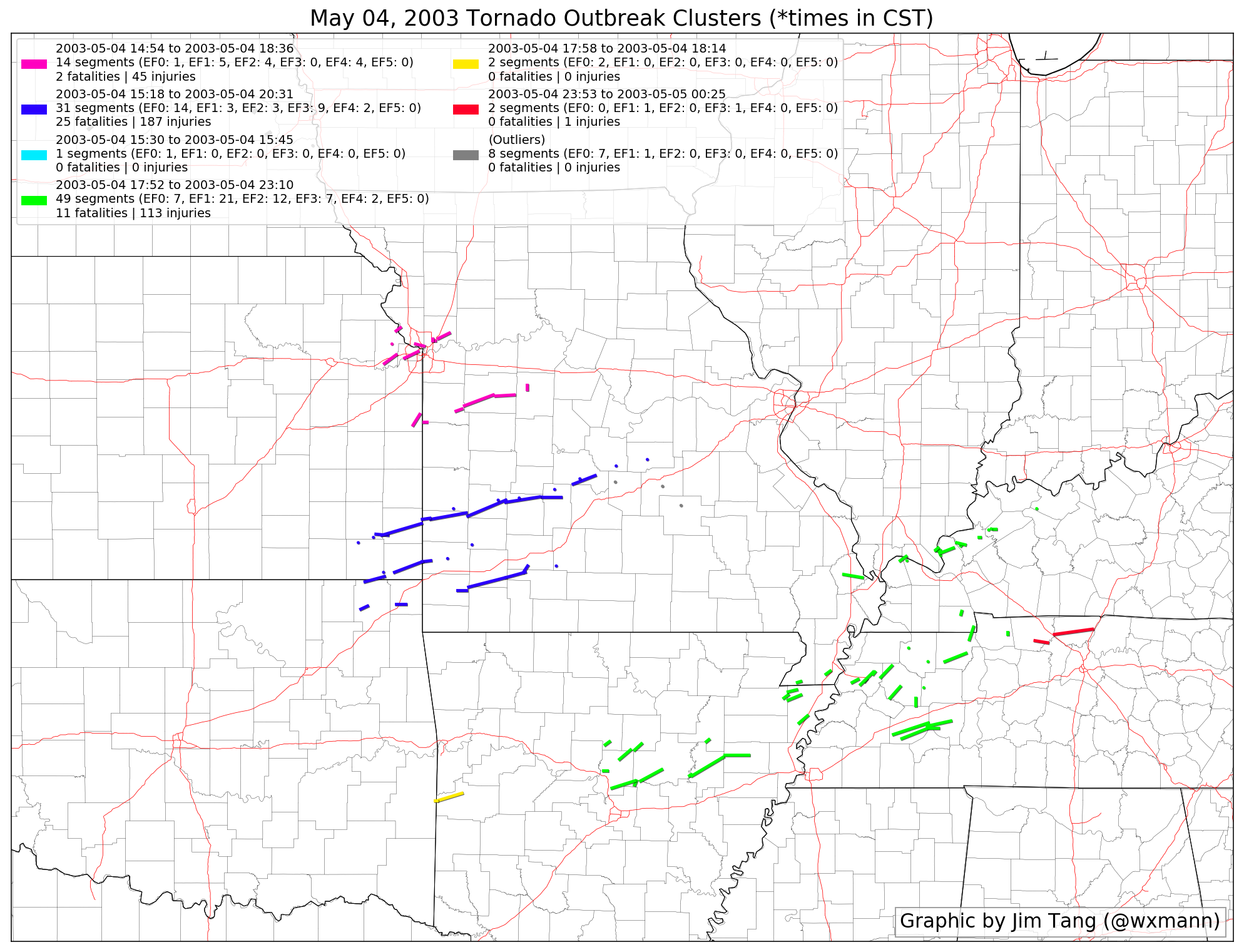
The Kansas City area tornadoes, the devastating long-track tornadoes that affected southeast KS and southwest MO, and the tornadoes that included the Jackson, TN EF4 are highlighted nicely here.
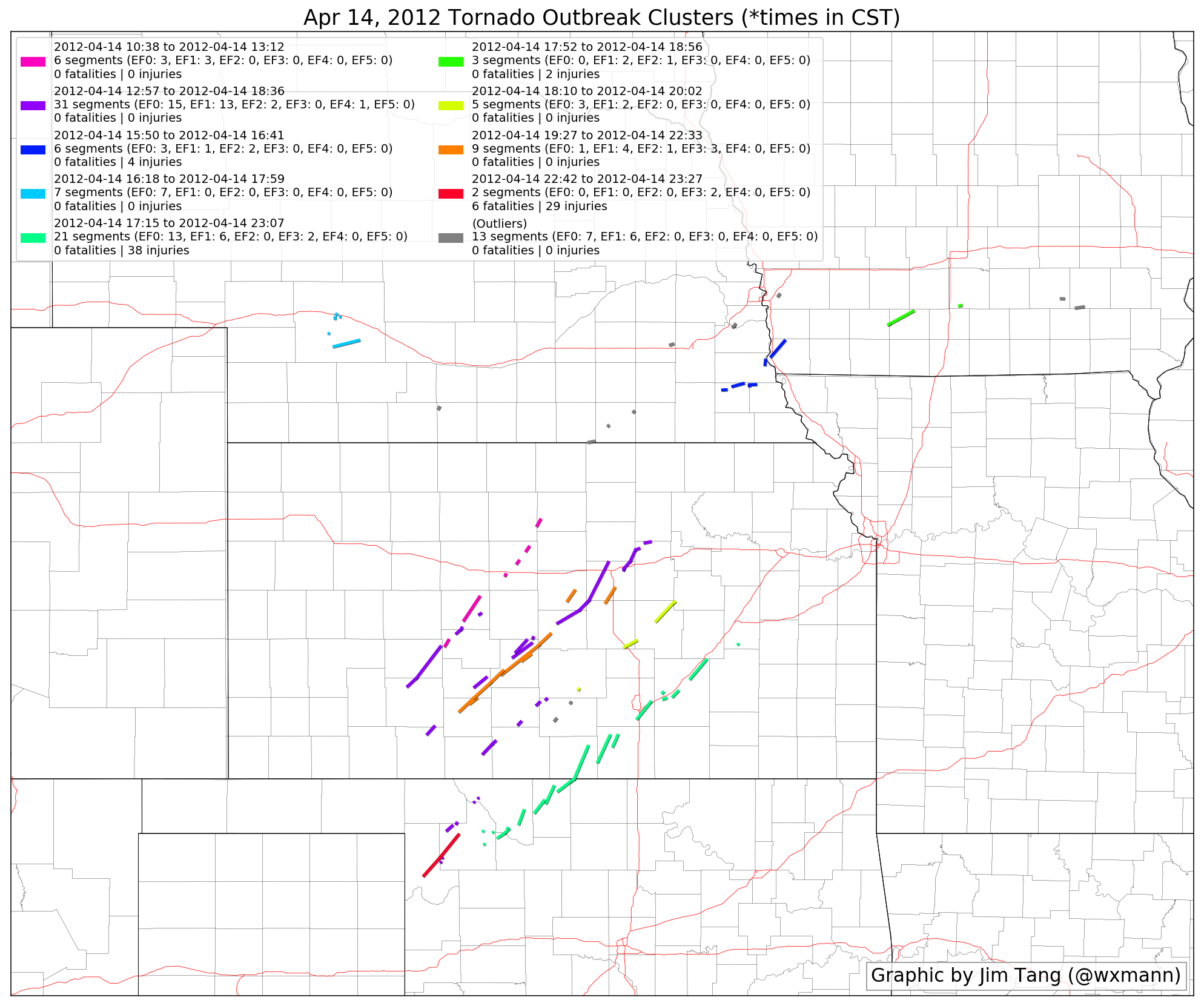
Clustering can untangle the progression of an outbreak where multiple rounds of tornadoes track over similar areas, and the April 2012 outbreak is a prime example of this.
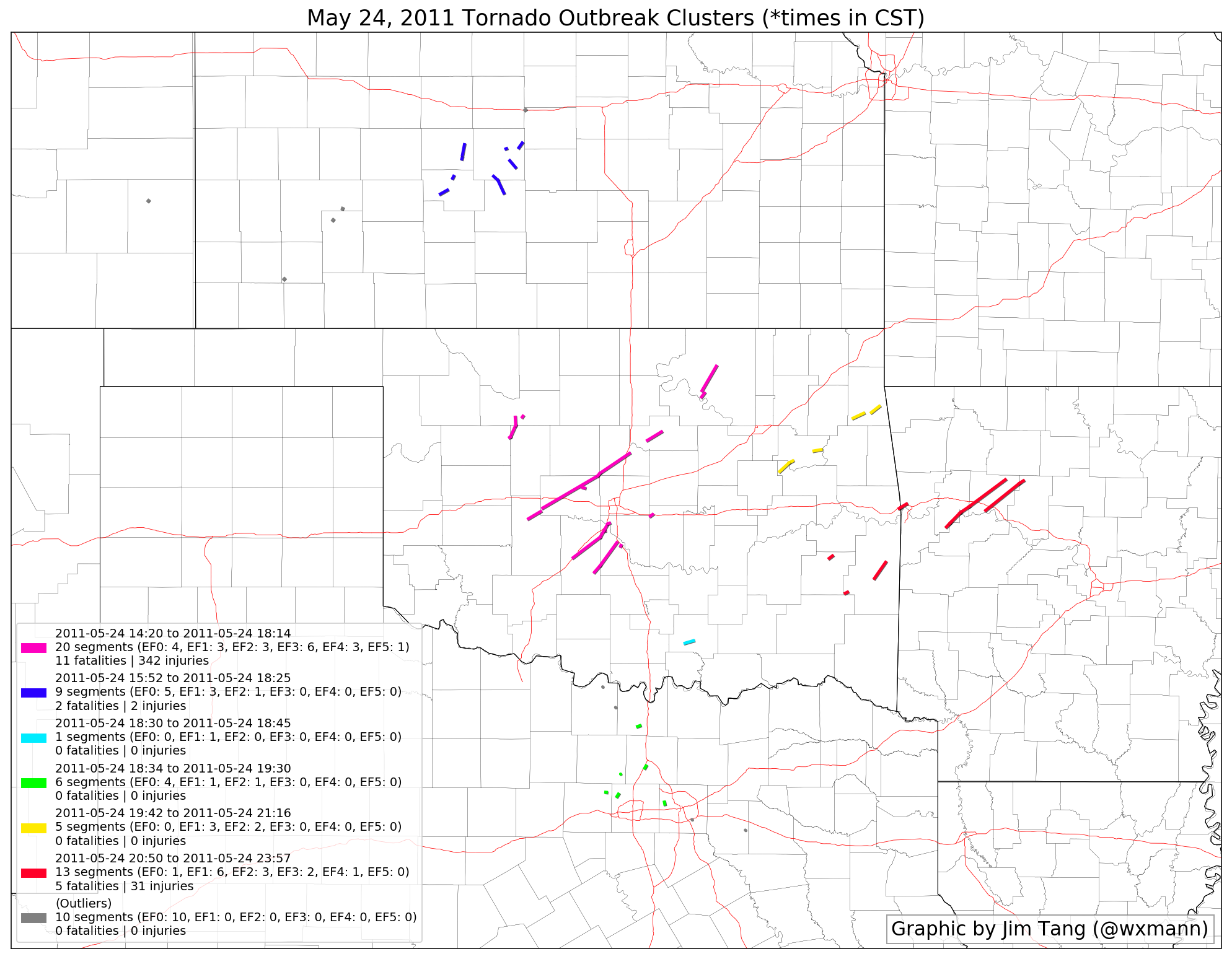
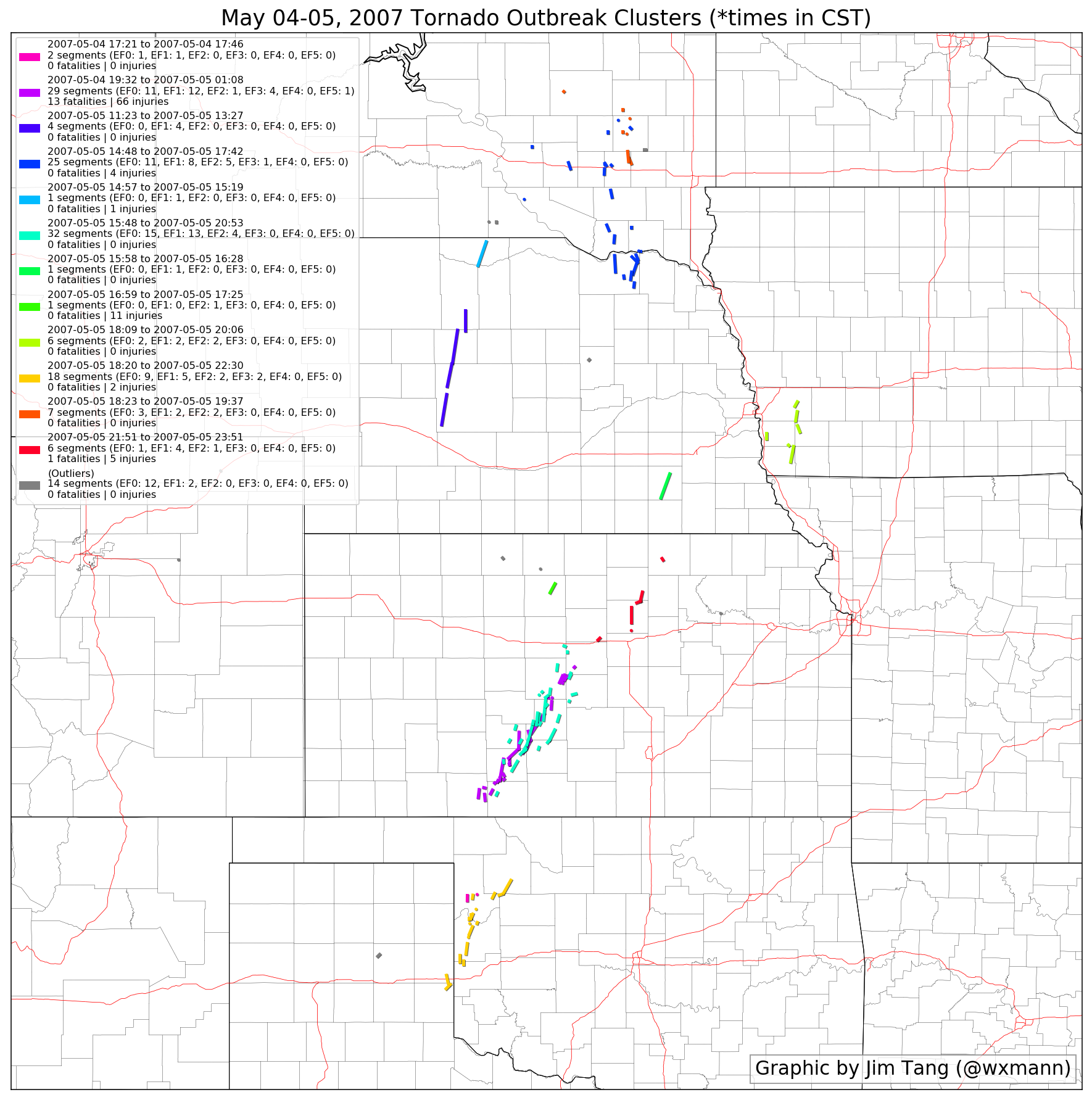
This example illustrates clustering on multi-day events. Note the overlapping tracks spanning two days in western Kansas.
This clustering technique offers some positives compared to the typical tornado day classifications. There are also some areas which might be better worked out in the future. In additional examinations of this technique, I will look at how it can be applied to chasing more specifically, and then later we’ll examine an outbreak in depth.
A dip in the jet stream is blasting toward the central United States and poised…
A historic storm system swept through the central, southern and eastern U.S. from Friday through…
In a field historically dominated by men, Jen Walton has emerged as a transformative figure…
Jason Persoff, MD, SFHM, is recognized globally for his expertise in storm chasing. He earned…
Tornado numbers were near or above average. A chase season peak in June provided numerous…
One of the more widespread tornado outbreaks in years, from Iowa and Illinois to Arkansas.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
View Comments
Very interesting, and you may be on to something here. Looking forward to the remaining entries on the topic!